RAID, orRedundantArray ofIndependent (orInexpensive)Disks, is a data storage technology used for data redundancy (protection against hardware failure), performance gain, or a combination of both.
The various RAID types (levels) store data differently, focus on different things (fault tolerance, throughput, cost), and as such, are suited for different situations. And there’s also the matter of RAID’s effectiveness in this current day and age.
With the advent of alternative technologies like SSDs and Erasure Coding, the question looms; is RAID still worth it? We’ll discuss all these and similar topics in this article.

What is RAID? How Does It Work
RAID is a storage technology used to set up multiple physical disks as a single logical disk called a Logical Unit Number (LUN). Generally speaking, in a RAID setup, data is stored across multiple disks, with the primary objective of data redundancy and/or performance improvement.
Data redundancy increases reliability by acting as a safety net against disk failure. Similarly, combining the specs of multiple disks provides significant performance boosts for I/O operations.
Of course, this is only a broad description. The degree to which the array focuses on redundancy or performance is dependent on the type of RAID used, typically referred to as RAID levels. Some are designed for one exclusive purpose, while others offer the best of both worlds.
TheStandard RAID Levelsare RAID 0 – RAID 6, but there are numerous other levels of RAID that fall under categories like Nested RAID and Non-Standard RAID. We’ll talk about all these in further detail later, but for now, let’s just end it with a brief introduction.
As for how RAID actually works, it implements techniques like data striping, disk mirroring, and parity. Depending on the RAID level, one or any combination of these techniques could be used.
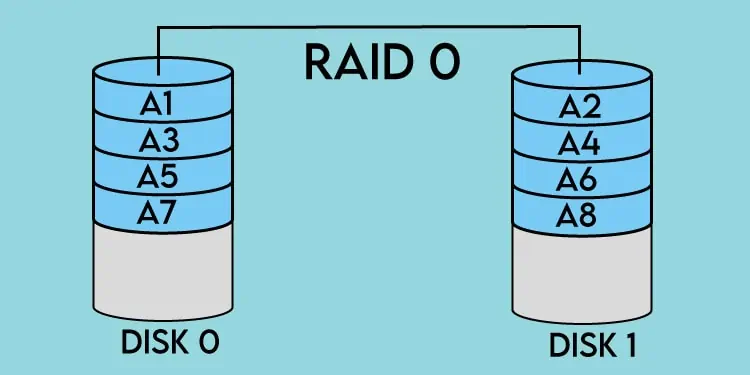
Data stripingis the process of splitting consecutive segments of logically sequential data on different disks. By concurrently accessing the data spread across multiple disks, you get to utilize the combined data throughput, which basically leads to improved performance.
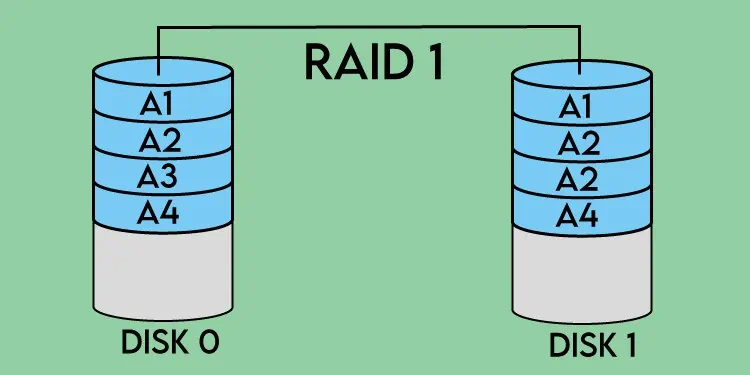
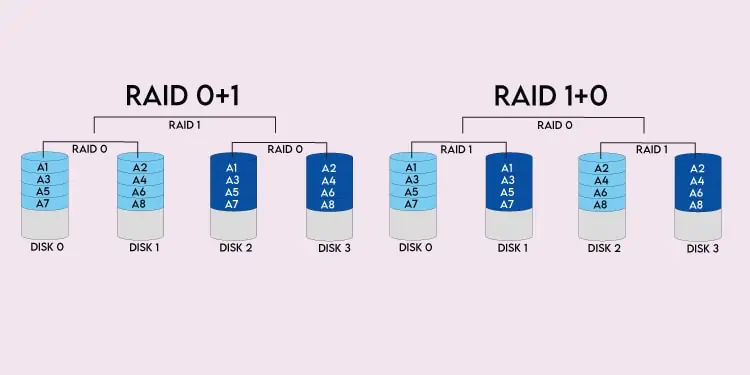
Mirroringis self-explanatory – the data from one disk is copied onto another. This makes the data on one disk redundant, but it’s intended as this allows data to be recovered in case one of the disks in the array fails.
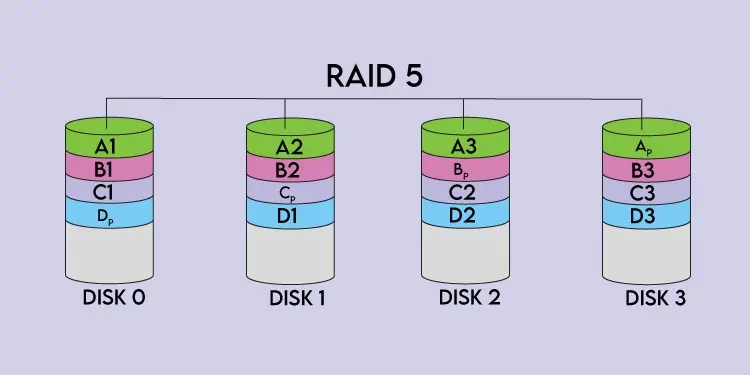
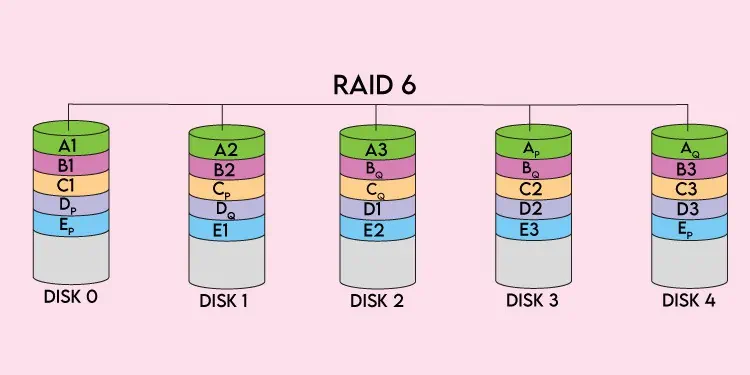
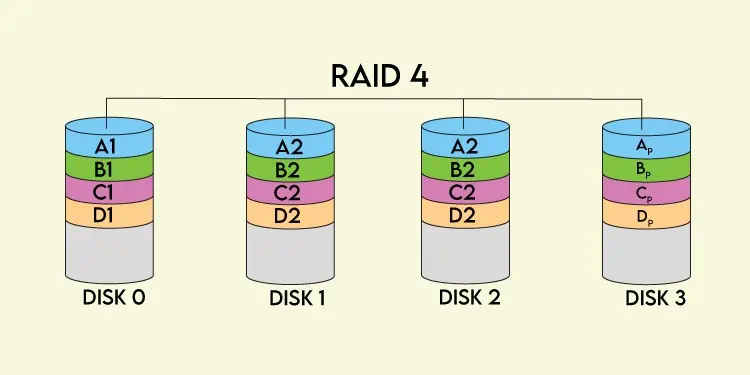
Parityis an error protection technique commonly used to provide fault tolerance and achieve redundancy. Parity data is either stored on a dedicated disk or spread out across all the disks, and when any disk in the array fails, you may swap it out for a fresh disk and utilize the parity data and data from the other disks to rebuild the lost data.
Generally, basicXORis performed on the disks’ data to calculate the parity data, but certain RAID levels like RAID 2 or RAID 6 use dedicated parities, which we’ve talked about further in the article.
Finally, there’s the matter ofRAID implementation. The RAID array can be managed either by a dedicated RAID controller, software-based implementations (md, ZFS, etc.), or firmware and driver-based implementations.
Physical RAID controllers can be pricy, while software controllers are free or affordable. However, as software controllers are dependent on the host machine for resources, the RAID performance boost is impacted as well. Generally, RAID 0 – 4 can be managed with software controllers, while RAID 5 and higher levels require a physical RAID controller.