Even though its been around for over 50 years, RAID is still very popular, particularly in enterprise environments. Overall, it’s quite an achievement for any technology to be relevant for this long.
If we focus on RAID’s status in the present day, some RAID levels are certainly more relevant than others. RAID 5 specifically has been one of the most popular RAID versions for the last two decades.
As disk sizes have increased exponentially, it does beg the question, though; is RAID 5 still reliable? To answer this question, we’ll first have to talk about what RAID 5 exactly is, it’s working mechanisms, applications, and flaws.
RAID 5 uses block-interleaved distributed parity. To understand this, we’ll have to start with the basics of RAID.
RedundantArray ofIndependentDisks (RAID)is basically data storage technology that’s used to provide protection against disk failure through data redundancy or fault tolerance while also improving overall disk performance.
RAID systems implement techniques like striping, mirroring, and parity.Stripingspreads chunks of logically sequential data across all the disks in an array which results in better read-write performance.

Parity, in the context of RAID, is recovery data that is written to a dedicated parity disk or spread across all disks in the array. If a disk in the array fails, this parity data, along with the data on the remaining working drives, can be used to reconstruct the lost data.
How Does RAID 5 Work?
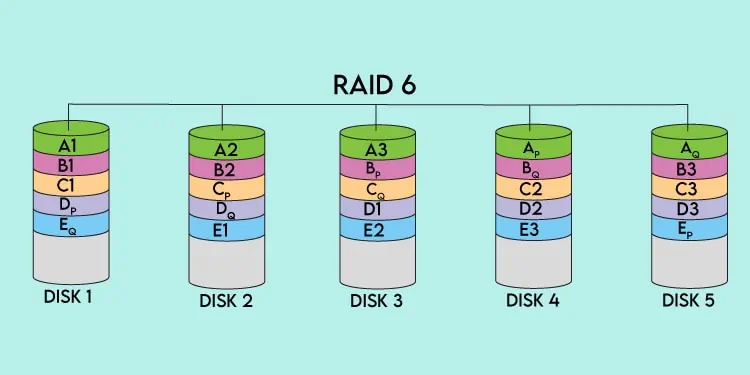
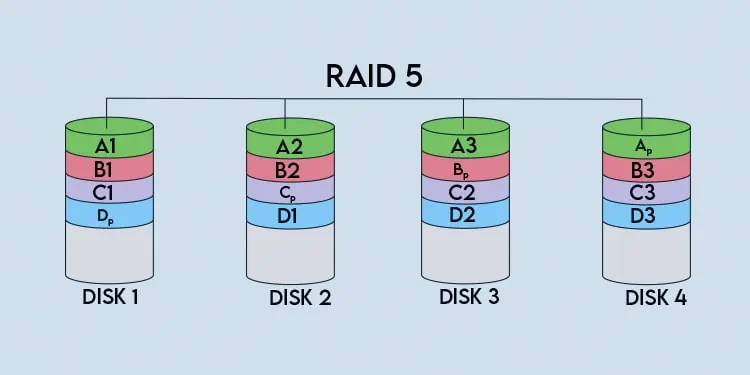
RAID 5 arrays useblock-level stripingwithdistributed parity. As atleast two disks are required for striping, and one more disk worth of space is needed for parity, RAID 5 arrays need at least3disks. Let’s take a 4-disk RAID 5 array as an example to understand better how it works.
When writing to the array, ablock-sized chunkof data (A1) is written to the first disk. This chunk of data is also referred to as astrip. The size of the block is called thechunk size, and its value varies as it’s up to the user to set.
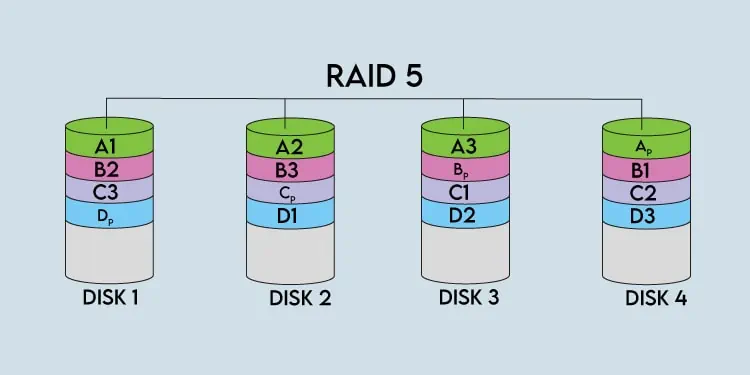
Continuing with the write operation, the next logically consecutive chunk of data (A2) is written to the second disk and the same with the third (A3). As data blocks are spread across these three strips, they’re collectively referred to as astripe.
Stripe size, as the name implies, refers to the sum of the size of all the strips or chunks in the stripe. Generally, hardware RAID controllers use stripe size, but some RAID implementations also use chunk size.
Continuing again, after data is striped across the disks (A1, A2, A3), parity data is calculated and stored as a block-sized chunk on the remaining disk (Ap). With this, one full stripe of data has been written.

In our example, the same process repeats again as data is striped across three disks while the fourth disk stores parity data. To put it simply, this continues until the write operation completes.
But there are some more things to cover here, such as how parity data is actually calculated and the layout of data and parity blocks in the array. So, let’s shift the focus to those in the next section.